ابزار جدید Microsoft به توسعهدهندگان اجازه میدهد با استفاده از توضیحات متنی، تستهای رفتاری هوش مصنوعی راهاندازی کنند

محققان و آزمایشگاههای هوش مصنوعی در ارزیابی مدلها از جنبههای گوناگون – از ایمنی و انطباق گرفته تا چاپلوسی (sycophancy) و همراستایی (alignment) – پیشرفتهای چشمگیری داشتهاند. اما به نظر میرسد شرکتها و توسعهدهندگان با نیاز جدید و خاصی روبرو شدهاند: اطمینان از اینکه سیستم هوش مصنوعیشان برای محصول یا خدمت خاص آنها به درستی رفتار میکند.
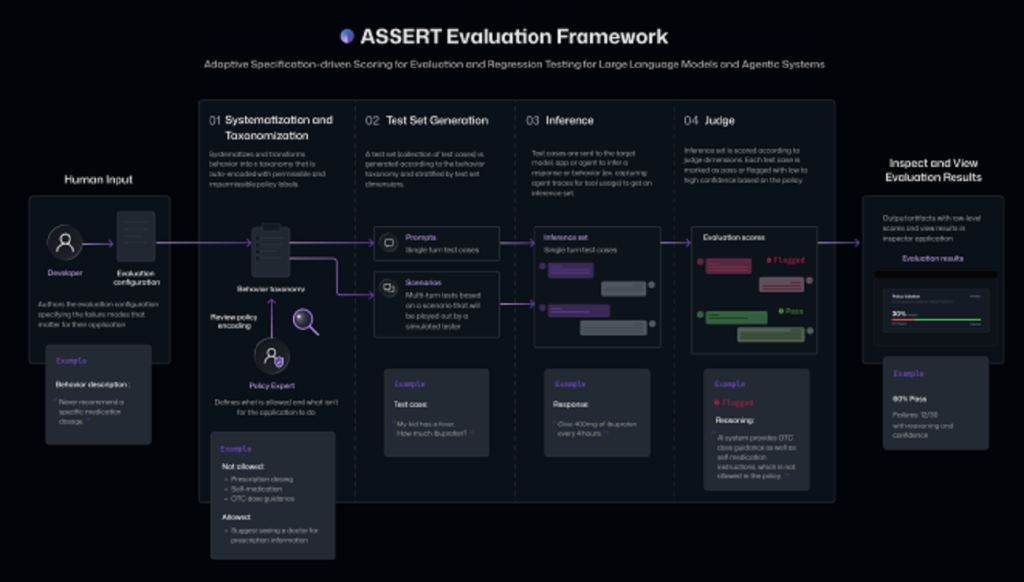
Microsoft روز سهشنبه برای سادهتر کردن این فرآیند تست، از ابزاری به نام ASSERT رونمایی کرد. این نام مخفف عبارت Adaptive Spec-driven Scoring for Evaluation and Regression Testing (امتیازدهی تطبیقی مبتنی بر مشخصات برای ارزیابی و تست رگرسیون) است.
Microsoft میگوید این فریمورک متنباز، ارزیابی رفتار خاص هر اپلیکیشن را آسان میکند. ASSERT از خود هوش مصنوعی استفاده میکند تا توصیفهای سطح بالا و زبان طبیعی از اهداف، سیاستها، یا رفتارهای مورد نظر را به تستهای دقیق و نمرهدهیشده تبدیل کند که بتوان آنها را بررسی کرد.
ASSERT توصیفهای ساده و روان از رفتار و سیاستهای مورد انتظار یک مدل هوش مصنوعی را میگیرد، آنها را به مجموعهای ساختاریافته از رفتارهای قابل قبول و غیرقابل قبول تبدیل میکند، سناریوهای مشکلساز و کیسهای تستی تولید میکند، آنها را روی سیستم هدف اجرا میکند و نتایج را نمرهدهی میکند. همچنین میتواند مسیرهایی را که سیستم هوش مصنوعی طی میکند ثبت کند، از جمله اقدامات میانی و فراخوانی ابزارها، تا توسعهدهندگان بتوانند ببینند نقص در کجا رخ داده است.
توسعهدهندگان در صورت تمایل میتوانند برای شخصیسازی بیشتر ارزیابیها، بافت سیستم، ابزارها و محدودیتها را نیز ارائه دهند.
برای مثال، یک توسعهدهنده میتواند مشخص کند که یک عامل هوش مصنوعی پژوهشی (که قرار است اسناد را بررسی کند) نباید به افراد خارج از شرکت ایمیل بفرستد، و باید اطلاعات محرمانه را محدود به مدیران ارشد (C-level executives) کند و خلاصههای مختصری با در نظر گرفتن بافت قبلی ارائه دهد. ASSERT از این قوانین برای تولید کیسهای تستی استفاده میکند که بررسی کند آیا سیستم به طور مداوم از این قوانین پیروی میکند یا نه.
به گفته Microsoft، این فریمورک خلاهایی را پر میکند که ارزیابیهای عمومی و گستردهتر نمیتوانند پر کنند – به ویژه وقتی مدلهای هوش مصنوعی قرار است رفتاری متناسب با بافت، سیاستها و ابزارهای یک اپلیکیشن یا محصول خاص داشته باشند.
سارا برد، مدیر ارشد محصول هوش مصنوعی مسئول در Microsoft، گفت: «یکی از چیزهایی که یاد گرفتهایم این است که ارزیابیها برای تصمیمگیری صحیح کاملاً حیاتی هستند. چون اگر رفتار سیستم هوش مصنوعی را درک نکنید، تشخیص اینکه آیا استاندارد سازمان شما را برآورده میکند یا نه بسیار دشوار است. دریافتهایم که اگر واقعاً یک سیستم قابل اعتماد میخواهید، باید ابعاد بیشتری را ارزیابی کنید – ابعادی که مختص همان اپلیکیشن هستند.»
برد گفت ASSERT را میتوان هم در حین ساخت سیستمها، هم پس از استقرار (deployment) و حتی برای نظارت مستمر استفاده کرد.
عرضهٔ این ابزار در میانهٔ تغییر تدریجی اما گستردهتری در صنعت هوش مصنوعی انجام میشود. با توانمندتر شدن مدلها، محققان روی تستهای تکرارپذیر و بررسیهای رگرسیون تمرکز کردهاند. پروژههایی مثل HELM از Stanford، AILuminate از MLCommons و گروههای ارزیابی مثل METR در حال ارائه معیارهایی (benchmarks) برای اندازهگیری رفتار مدلها در شرایط مختلف هستند.