Microsoft روش بهتری را در اختیار توسعهدهندگان قرار میدهد تا رفتار عامل هوش مصنوعی را کنترل کنند

از آنجا که عاملهای هوش مصنوعی روزبهروز توانمندتر میشوند، شرکتهایی که با شتاب تمام در تلاشند آنها را در سراسر برنامهها، گردشهای کاری و محصولات خود به کار گیرند، با چالش تازهای روبرو شدهاند: اطمینان از اینکه یک عامل در محیطهای مختلف، دقیقاً همان کاری را انجام دهد که از او انتظار میرود.
Microsoft در تلاش است این مسئله را با یک استاندارد متنباز جدید به نام Agent Control Specification (ACS) حل کند. هدف این استاندارد، ارائهٔ روشی منسجمتر و دقیقتر به توسعهدهندگان برای کنترل کارهایی است که عاملهای هوش مصنوعی مجاز به انجام آن هستند.
این استاندارد اساساً به تیمهای توسعه، انطباق (compliance) و امنیت اجازه میدهد سیاستهای خود را برای عاملها تعریف کنند. قوانین میتوانند مشخص کنند عامل چه کاری میتواند انجام دهد، چه کاری نباید انجام دهد، چه زمانی یک انسان باید کاری را تأیید کند، و چه شواهدی باید برای بازبینی بعدی ثبت شود. این فایلهای سیاستی در چندین «نقطهٔ رهگیری» (interception point) در حالی که عامل مشغول انجام یک وظیفه است بررسی میشوند تا اطمینان حاصل شود که از محدودهٔ تعیینشده خارج نمیشود.
این استاندارد در شرایطی ارائه میشود که توسعهدهندگان در حال بداههپردازی برای کنترل آنچه هوش مصنوعی میبیند و انجام میدهد هستند – به ویژه در شرایطی که گفتگوها بر روی گردشهای کاری هوش مصنوعی متمرکز شده که به دلیل سوءاستفاده از ابزارها یا اقدامات ناخواسته، به شکستهای زنجیرهای (cascading failures) منجر میشوند.
امروزه، توسعهدهندگان ممکن است دستورالعملهایی را در پرامپت سیستم مشخص کنند، بررسیهای سفارشی به کد برنامه اضافه کنند، یا از طبقهبندیکنندهها (classifiers) برای شناسایی ورودیها و خروجیهای مشکلساز استفاده کنند. این رویکردها کار میکنند، اما اغلب شرکتها را با کنترلهایی پراکنده مواجه میسازند که حسابرسی آنها دشوار است و استفادهٔ مجدد از آنها در فریمورکها، رابطها و سیستمهای مختلف سختتر هم میشود.
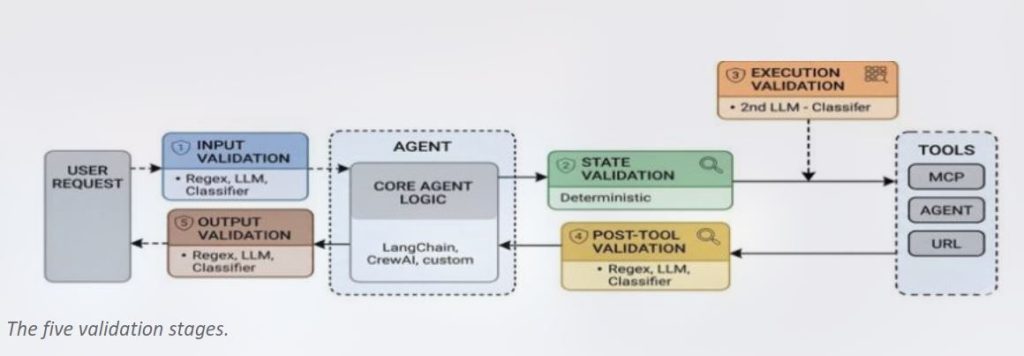
هدف ACS این است که این کنترلها را در یک لایهٔ حاکمیتی مشترک ادغام کند. Microsoft میگوید میتوان از این استاندارد برای بررسی پایبندی عامل به محدودههای تعیینشده در چندین نقطه از گردش کار آن استفاده کرد – پیش از دریافت ورودی، پیش از فراخوانی یک ابزار، پس از بازگشت نتیجه از سوی ابزار، و پیش از ارسال پاسخ نهایی به کاربر. یک سیاست ممکن است اقدامی را مجاز کند، آن را مسدود کند، اطلاعات حساس را پاکسازی (redact) کند، یا حتی از یک انسان بخواهد آن را تأیید کند.
توسعهدهندگان همچنین میتوانند طبقهبندیکنندههایی (classifiers) برای ورودیها و خروجیها وارد کنند تا اطلاعات را دستهبندی کرده، نتایج را پیشبینی کنند، یا تعیین کنند عامل چگونه باید پاسخ دهد. همچنین میتوانند مدلهای زبانی بزرگ (LLM) را با پرامپت اضافه کنند تا به عنوان «داور» سیاستها عمل کنند، و منطقی برای بررسی فراخوانی ابزارها، انتخاب ابزار، دقت ورودی، نحوهٔ استفاده از خروجی، و پاسخها اضافه نمایند.
و از آنجا که این سیاستها را میتوان به صورت فایلهای مستقل (تکفایل) نوشت، میتوان آنها را همراه با عاملها (agents) بستهبندی کرد – به طوری که یک سیاست امنیتی بتواند عامل را در فریمورکها و محیطهای مختلف دنبال کند.
ACS به صورت یک SDK همراه با افزونههایی (plug-ins) برای موارد زیر عرضه میشود:
-
LangChain
-
OpenAI Agents SDK
-
Anthropic Agents SDK
-
AutoGen
-
CrewAI
-
Semantic Kernel
-
MCP tools